Observability in der Praxis
Im ersten Blogbeitrag zu diesem Thema haben wir uns angesehen, wie Logs, Traces und Metriken zusammenspielen. Nun wollen wir diese Konzepte anhand einer praktischen Demo-Anwendung erlebbar machen: Wir haben ein einfaches Angular-Frontend, das verschiedene Endpoints in einem minimal gehaltenen ASP.NET Core Backend aufruft. Diese Endpoints antworten mal erfolgreich (HTTP 200), mal mit speziellen Statuscodes (404, 400) oder lösen sogar echte Fehler (HTTP 500) aus. Auf diese Weise können wir anhand der erzeugten Observability-Signale direkt erkennen, was im System passiert – und wie Autoinstrumentation uns dabei unterstützt.
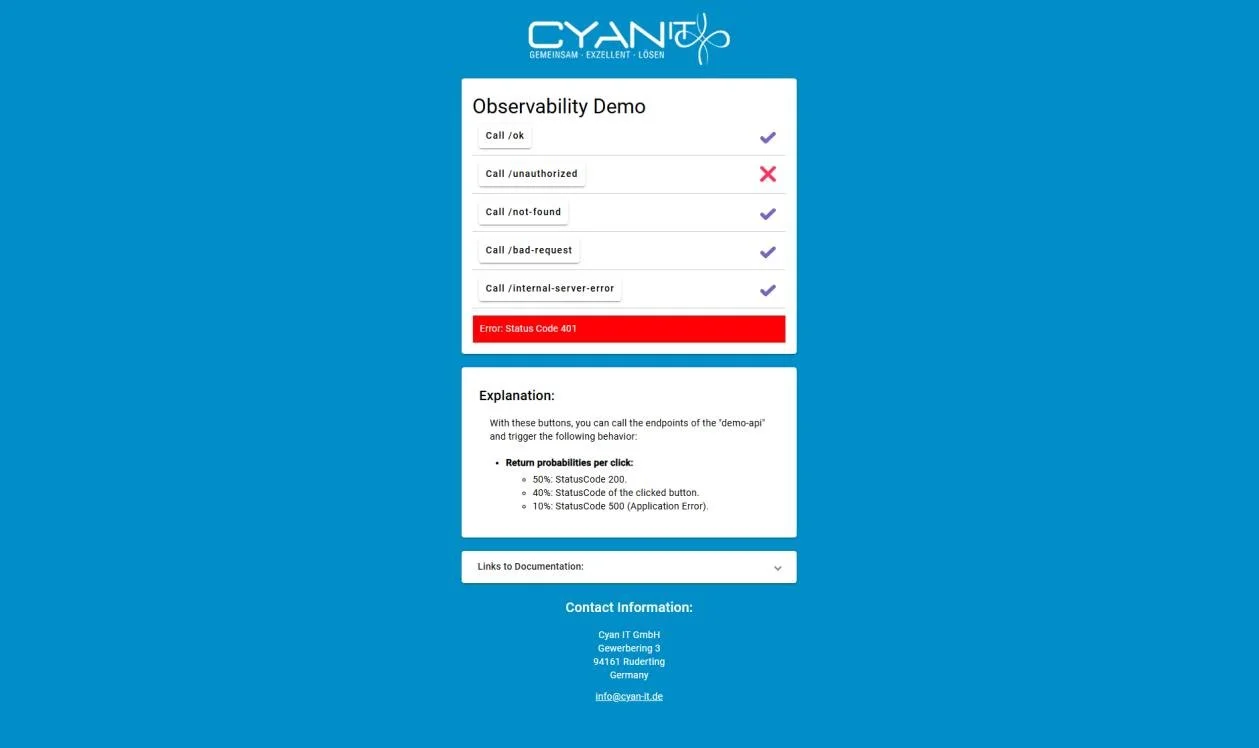
Der Tech-Stack und die Tools
Angular Frontend: Eine einfache Web-Oberfläche, über die Requests an das Backend geschickt werden.
ASP.NET Core Minimal API Backend: Endpunkte sorgen für bewusst variierendes Verhalten, um unterschiedliche Systemzustände zu simulieren.
OpenTelemetry: Das Herzstück unserer Observability-Integration. OpenTelemetry erfasst standardisiert Logs, Traces und Metriken.
Prometheus, Loki und Tempo: Diese Tools sammeln Metriken, Logs und Traces und stellen sie so bereit, dass wir sie leicht analysieren können.
Grafana: Unser Visualisierungstool, mit dem wir Dashboards erstellen, Metriken im Zeitverlauf ansehen sowie von Logs direkt zu den zugehörigen Traces springen können.
Autoinstrumentation: Mehr Einblick bei weniger Aufwand
Der große Vorteil von OpenTelemetry ist die Möglichkeit der Autoinstrumentation. Das heißt, wir müssen nicht überall im Code manuell Logging- oder Tracing-Logik hinzufügen. Stattdessen kommen Bibliotheken und Plugins zum Einsatz, die bei gängigen Frameworks und Technologien automatisch wichtige Ereignisse erfassen. So erhalten wir schnell ein umfassendes Bild des Systemverhaltens, ohne an jeder Stelle eigenen Telemetrie-Code einstreuen zu müssen.
Autoinstrumentation im Angular-Frontend mit Codebeispielen
Im Angular-Frontend nutzen wir das Paket @opentelemetry/auto-instrumentations-web, um typische Browser-Aktionen und insbesondere auch ausgehende HTTP-Requests automatisch mit Traces zu versehen. Auf diese Weise entstehen ohne großen Mehraufwand vollständige Tracing-Informationen, die uns helfen, spätere Probleme oder Performance-Engpässe einfacher zu analysieren.
Schritt 1: Konfiguration in instrumentation.ts
In unserer instrumentation.ts-Datei erstellen wir einen WebTracerProvider, verknüpfen ihn mit einem OTLP-Exporter, um die Traces an den OpenTelemetry Collector zu senden, und registrieren die Autoinstrumentation. Dadurch werden automatisch XML- und Fetch-Requests getraced.

Mit dieser Konfiguration werden alle ausgehenden HTTP-Requests automatisch erfasst. Doch manchmal möchten wir noch etwas mehr Kontrolle darüber haben, wann Spans gestartet und beendet werden.
Schritt 2: HTTP-Interceptor für Feintuning
Um sicherzustellen, dass wir auch wirklich jeden Request sauber getraced bekommen und gegebenenfalls zusätzliche Attribute oder Fehlerkennzeichnungen setzen können, verwenden wir einen Angular HTTP-Interceptor. Dieser startet bei jedem Request einen neuen Span und beendet ihn, sobald die Antwort oder ein Fehler vorliegt.
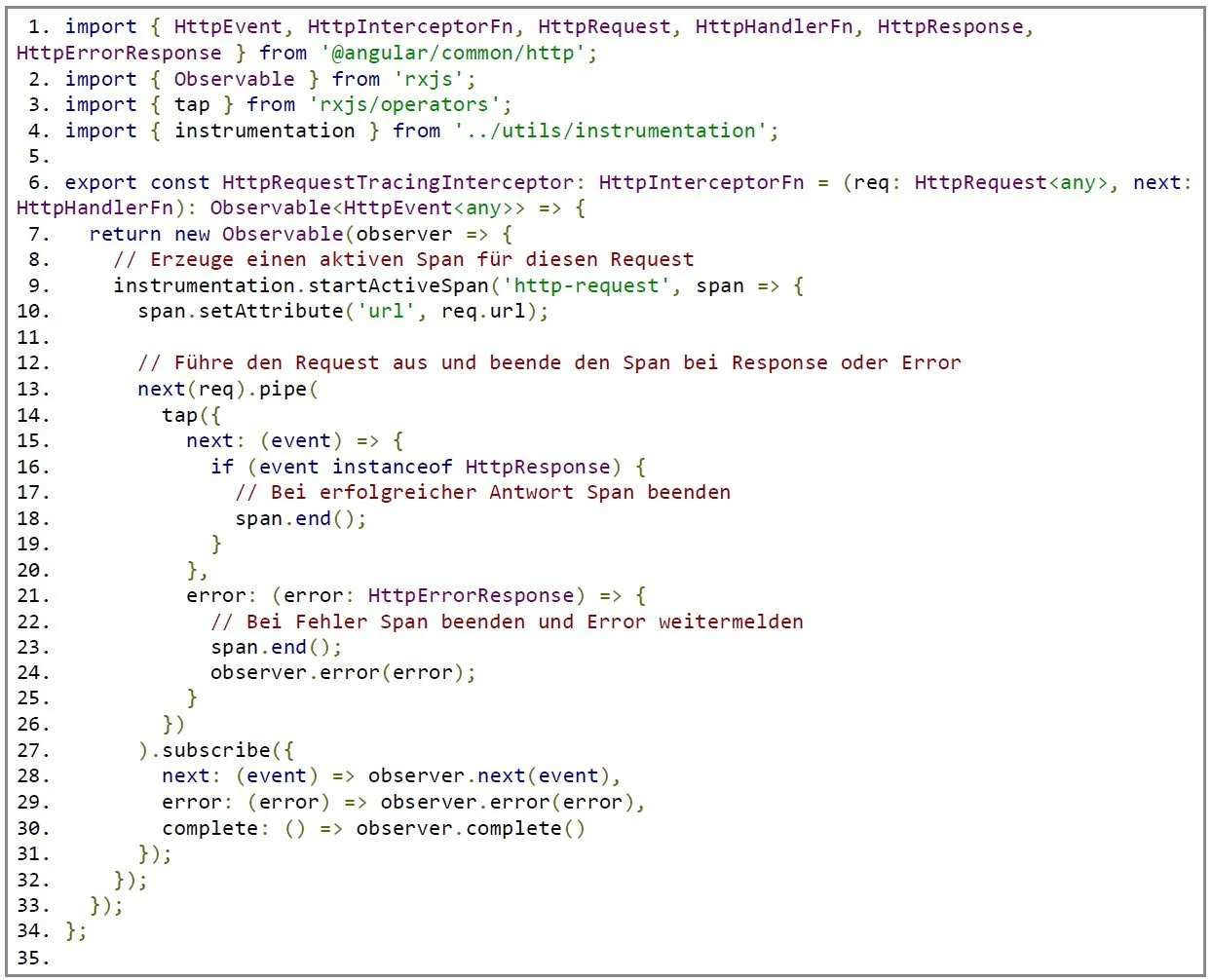
Mit diesem Interceptor ergänzen wir die durch die Autoinstrumentation bereits erzeugten Traces um eigene, kontextbezogene Informationen, etwa indem wir den Spans URL-Attribute hinzufügen oder Fehler eindeutig markieren. Das Endergebnis ist eine vollständige Transparenz über die ausgehenden Requests im Angular-Frontend.
Ergebnis: Ein Klick im Angular-Frontend löst eine Kette von Spans und Traces aus, die sich lückenlos von der Benutzeraktion bis zum Backend-Endpunkt verfolgen lassen.
Autoinstrumentation im .NET-Backend mit Codebeispielen
Im .NET-Backend setzen wir auf OpenTelemetry, um eingehende HTTP-Requests, ausgehende HTTP-Client-Anfragen und eigene Logiken automatisch oder halbautomatisch mit Traces, Metriken und Logs zu versehen. Durch diese AutoiInstrumentation erhalten wir einen umfassenden Einblick in das Verhalten unserer Anwendung:
Schritt 1: Konfiguration über OpenTelemetryExtensions
In der Klasse OpenTelemetryExtensions konfigurieren wir, welche Quellen getraced, welche Metriken erhoben und wie diese Daten exportiert werden. Mit AddAspNetCoreInstrumentation() werden alle eingehenden Requests automatisch erfasst, AddHttpClientInstrumentation() deckt ausgehende HTTP-Aufrufe ab, und AddOtlpExporter() schickt die Telemetriedaten an den OpenTelemetry Collector.

Mit dieser Konfiguration werden eingehende und ausgehende HTTP-Requests sowie Metriken automatisch erfasst. Die Daten gehen direkt an den OpenTelemetry Collector und lassen sich anschließend in Grafana, Loki oder Tempo visualisieren und analysieren.
Schritt 2: Eigene ActivitySources in den Services
Um dort, wo es nötig ist, mehr Detailtiefe zu erreichen, können wir eigene ActivitySources nutzen. So lassen sich Abläufe innerhalb von Services präzise nachverfolgen. Bei Fehlern können wir etwa Status-Codes und aussagekräftige Tags setzen, um die spätere Fehlersuche zu erleichtern. Das Ergebnis ist ein vollständig durchinstrumentiertes Backend, in dem wir nicht nur wissen, dass ein Request fehlgeschlagen ist, sondern auch den genauen Grund nachvollziehen können – sei es eine interne Verzögerung oder ein zufällig eingetretener Fehler.


In diesen Beispielen starten wir bei jedem Methodenaufruf einen neuen Activity-Span, hängen Tags an (zum Beispiel Min, Max, Result oder DelayTime) und setzen im Fehlerfall einen entsprechenden Status. Die so erzeugten Spans sind über die definierte ActivitySource ("DemoApi.Services.Random" oder "DemoApi.Services.Delay") mit unserem Tracing verbunden und erscheinen später im Trace. So sehen wir nicht nur, dass ein Fehler aufgetreten ist, sondern auch wo und warum.
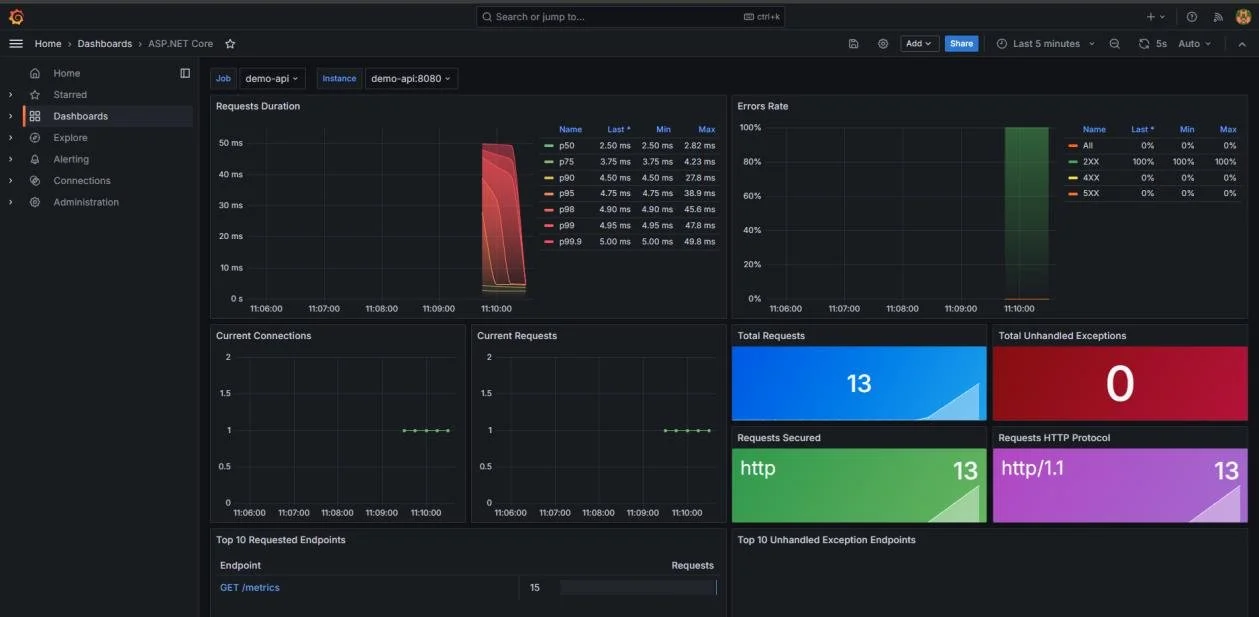
Visualisierung in Grafana: Metriken, Logs und Traces im Blick
Sobald unsere Anwendung läuft und Telemetriedaten produziert, können wir Grafana nutzen, um diese Daten in aussagekräftigen Dashboards darzustellen. Wie bereits erwähnt, haben wir in der Standardkonfiguration zwei Dashboards parat: ein Dashboard für ASP.NET Core Metriken und eines für Loki Logs. Über diese Dashboards lassen sich beispielsweise Request-Dauern, Antwortcodes und aktive Requests analysieren. Werfen wir einen Blick auf ein mögliches Setup:
Neben den Metriken ermöglichen die Loki-Logs eine tiefergehende Analyse: Über das Loki-Dashboard lassen sich Logs filtern, durchsuchen und live beobachten.
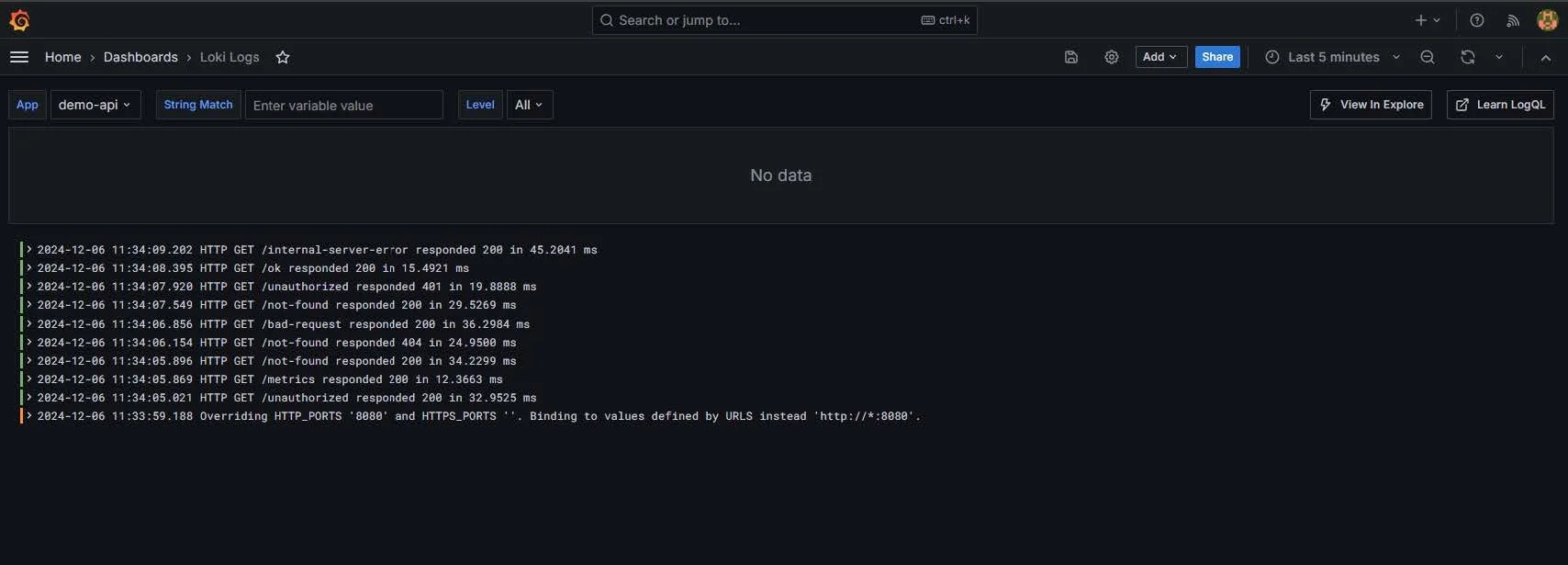
Zudem ist dank der integrierten „View Trace“-Funktion ein nahtloser Wechsel von einem Log-Eintrag zum zugehörigen Trace möglich. Dadurch wird es extrem einfach, die Kette von Ereignissen nachzuvollziehen, die zu einem bestimmten Fehler oder einer Auffälligkeit geführt hat.
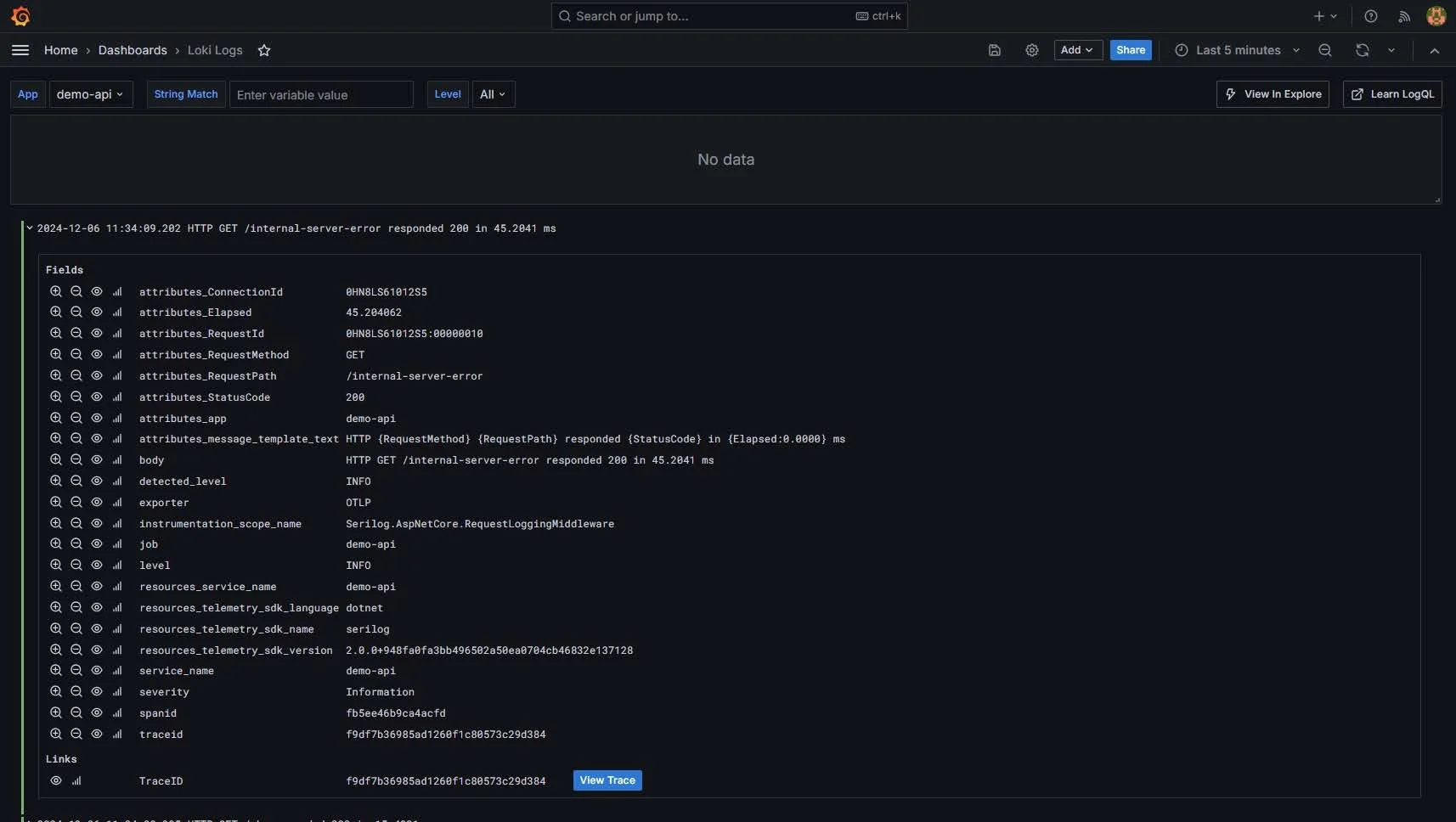
Mit einem Klick auf „View Trace“ öffnet sich die Tempo Data Source in Grafana. Hier lässt sich der komplette Trace einsehen, der zum ausgewählten Log-Eintrag gehört. Diese Darstellung zeigt ausführlich, welche Spans beteiligt waren, wie lange sie dauerten und an welcher Stelle ein Fehler auftrat. So haben wir innerhalb von Sekunden vom Aggregat der Metriken über die detaillierten Logs bis hin zur genauen Trace-Ansicht navigiert.
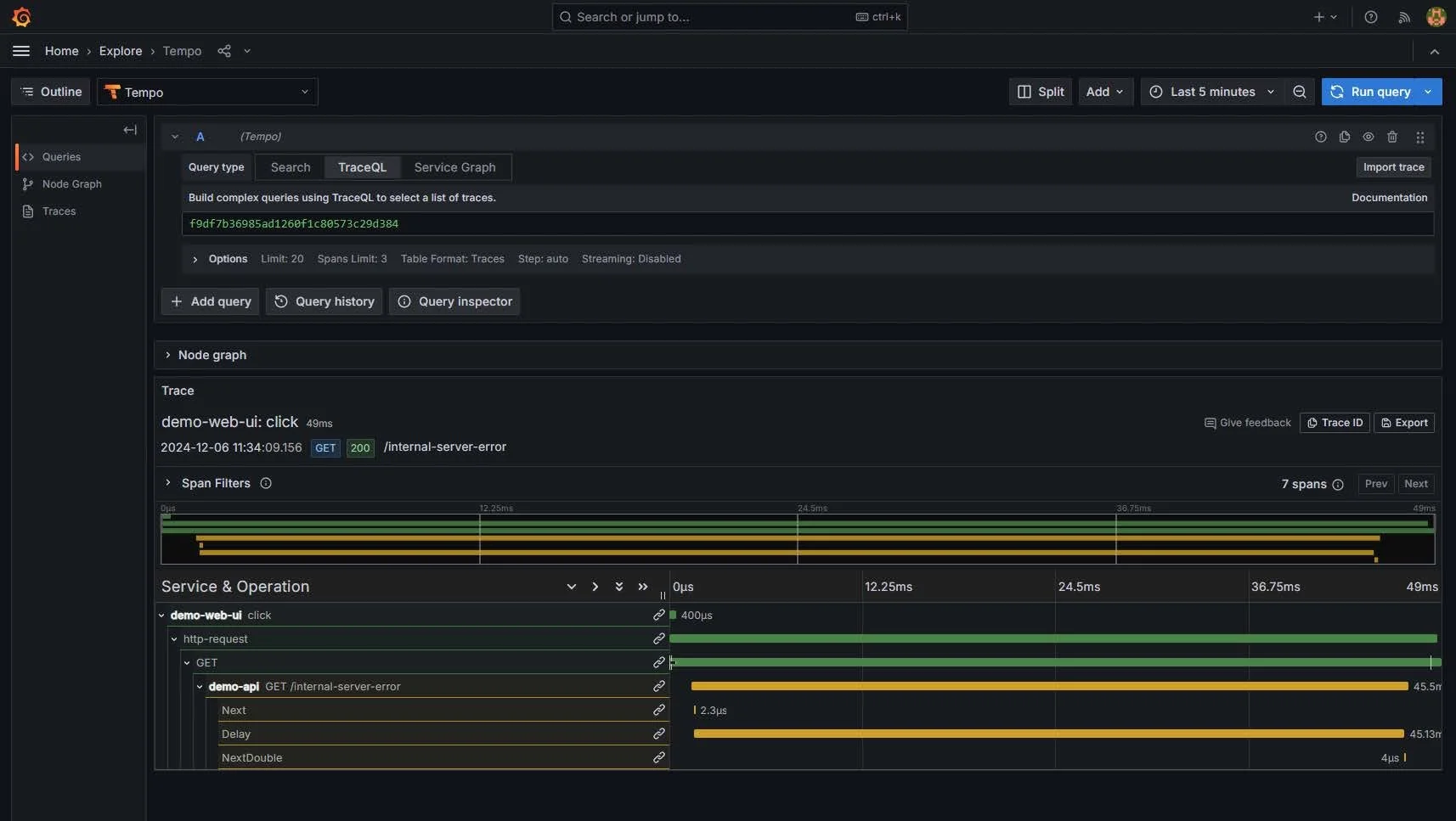
Durch diese End-to-End-Übersicht in Grafana ist es möglich, komplexe Zusammenhänge schnell zu erkennen: Wo treten Performance-Probleme auf? Welche Services sind betroffen? Welche Requests schlagen häufig fehl und warum? Das Zusammenspiel von Metrics, Logs und Traces wird so in einer einheitlichen, intuitiven Oberfläche zugänglich und erlaubt eine tiefgehende Analyse, ohne dass wir dafür aufwändig zwischen verschiedenen Tools oder Konsolen wechseln müssen.
Warum sich das lohnt
Durch diese Autoinstrumentation und ergänzende manuelle Aktivitäten erhalten wir ohne großen Mehraufwand einen tiefen Einblick in die Abläufe unseres .NET-Backends. Egal ob eingehende Requests, ausgehende HTTP-Aufrufe oder interne Logiken – alles wird transparent und nachvollziehbar, was bei der Diagnose von Problemen, Performance-Analysen und generell bei der Verbesserung unserer Anwendung enorm hilft.
Zusammengefasst
Angular-Frontend: Mithilfe von @opentelemetry/auto-instrumentations-web und einem dedizierten HTTP-Interceptor werden ausgehende Requests automatisch getraced. Wir erhalten dadurch vollständige Trace-Informationen über jede Benutzerinteraktion, ohne selbst Code für jede einzelne Anfrage schreiben zu müssen.
.NET-Backend: Durch die OpenTelemetry-Erweiterungen werden eingehende und ausgehende HTTP-Requests sowie Metriken automatisch erfasst. Eigene ActivitySources in den Services ermöglichen es zudem, bestimmte Abläufe oder Fehler präzise zu markieren. Damit entsteht ein durchgängiges Bild von allen relevanten Prozessen und Zuständen, vom ersten Klick im Browser bis zur Verarbeitung im Backend.
Das Zusammenspiel dieser Komponenten liefert uns ein aussagekräftiges, umfassendes Observability-Bild.